Цель и задача
Существует дерево категорий, сформированное по технологии NestedSets, а так же списки, подчиненыые определенным категориям. Например: таблица категорий фирм и таблица списка фирм. Для остроты ощущений усложним задачу, подставив не прямое подчинение фирмы категории, а через дополнительную таблицу, для того что бы была возможность фирму определять для разных категорий. Схему данных возьму существующую из одного из своих проектов:
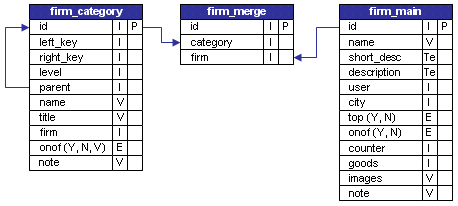
В общем-то нас интересуют не все поля, в частности:
- firm_category.id - идентификатор категории;
- firm_category.left_key - левый ключ узла;
- firm_category.right_key - правый ключ узла;
- firm_category.level - уровень узла;
- firm_category.firm - количество фирм в данной категории (включая подчиненные), наш счетчик;
- firm_merge.category - идентификатор категории фирмы;
- firm_merge.firm - идентификатор фирмы;
А таблица firm_main - использоваться и не будет...
Концепция
Процедуру обновления счетчиков мы добавим в наш модуль, но для начала определим концепцию и подводные камни:
-
Возьмем за правило, что все используемые в обработке поля имеют тип поля INT (ЦЕЛЫЙ)*. Во первых, это ускоряет обработку, а во вторых упрощает проверку передаваемых начальных данных;
-
Хотелось бы что бы процедура работала в двух режимах: обновление всего дерева и обновление только той части дерева, которое требуется (родительская ветка), но с учетом того, что один и тот же элемент списка может находится в различных частях дерева, то нам потребуется при обновлении каждого родительского узла проверять все подчиненные на предмет повтора элемента, что само по себе - не ускорит обработку, а в некоторых случаях даже замедлит, правда, это не относится структуре с прямым подчинением элемент => категория.Итак, ломать голову не будем, режим процедуры один - полное обновление дерева;
- Метод должен позволять указывать дополнительные условия обновления дерева, то есть если у нас есть выключенные категории, то учитывать их не нужно.
ПРИМЕЧАНИЕ: * в одной из статей (не моих), о технологии NestedSets, описывался принцип формирования НЕ целых ключей дерева, что позволяет ускорить процесс вставки и перемещения узлов дерева, но данная схема была описана учень скудно и, хочу заметить, при таком формировании ключей, можно практически забыть о проверке целостности дерева, а так же быстрый подсчет количества подчиненных узлов.
Код
Итак, код. В нем не используются никакие из методов модуля, а только сам объект.
sub optimize_counter {
# Получаем данные, где:
# $self - объект
# $child_table - имя подчиненной таблицы [firm_merge]
# $counter_field - имя поля счетчика в основной таблице [firm_category.firm]
# $parent_field - имя поля ID родителя в подчиненной таблице [firm_merge.category]
# $id_field - имя поля ID элемента списка в подчиненной таблице [firm_merge.firm]
# $where - дополнительное условие выборки для обоих таблиц [p => '...', c => '...']
my ($self, $child_table, $counter_field, $parent_field, $id_field, $where) = @_;
$id_field = 'id' unless $id_field;
# Формируем запрос на выборку узлов всего дерева, но сортировку производим в обратном порядке
my $sql = 'SELECT '.$self->{'id'}.' AS id, '.$self->{'level'}.' AS level
FROM '.$self->{'table'}.
($where->{'p'} ? ' WHERE '.$where->{'p'} : '').'
ORDER BY '.$self->{'left'}.' DESC';
my $sth = $self->{'DBI'}->prepare($sql); $sth->execute() || die $DBI::errstr;
# Определяем временные переменные цикла, где:
# $prev - уровень предыдущего узла
# @counter - счетчики по уровням
# @ids - ссылки на хеши ID элементов по уровням
my ($plev, @counter, @ids);
while (my $parent = $sth->fetchrow_hashref()) {
# Обнуляем счетчики и ID элементов при переходе на уровень ниже,
# но обнуляются только счетчики уровней ниже текущего
if ($$parent{'level'} >= $plev || !$plev) {
for (my $i = $plev; $i < $$parent{'level'} + 1; $i++) {
$counter[$i] = undef;
$ids[$i] = undef;
}
}
# Выбираем ID элементов списка подчиненного узлу, и в случае отсутсвия
# совпадения обновляем счетчики до корня дерева
my $sql = 'SELECT '.$id_field.' AS id
FROM '.$child_table.'
WHERE '.$parent_field.' = '.$$parent{'id'}.
($where->{'c'} ? ' AND '.$where->{'c'} : '');
my $sth = $self->{'DBI'}->prepare($sql); $sth->execute() || die $DBI::errstr;
while (my $child = $sth->fetchrow_hashref()) {
for (1..$$parent{'level'}) {
$ids[$_]->{$$child{'id'}}++;
$counter[$_]++ if $ids[$_]->{$$child{'id'}} < 2;
}
}
$sth->finish();
# Обновляем счетчик текущего узла
$self->{'DBI'}->do('UPDATE '.$self->{'table'}.'
SET '.$counter_field.'='.($counter[$$parent{'level'}] || ' 0').'
WHERE '.$self->{'id'}.'='.$$parent{'id'}.'
LIMIT 1');
# Обновляем временную переменную - уровень предыдущего узла
$plev = $$parent{'level'};
}
$sth->finish();
return 1
}
Конечно, данную процедуру не рационально использовать при обновлении данных "на лету", а вывести отдельной кнопкой. Так же она позволяет обрабатывать как структуры без прямой подчиненности так и с прямой.
| 
